


O que é a Deep Web?
Nosso primeiro desafio ao conhecer a Deep Web é defini-la. O termo “Deep Web” foi cunhado em 2001, em um artigo intitulado The Deep Web: Surfacing Hidden Value, de autoria de Michael K. Bergman.
Na época, Bergman definiu “Deep Web” como todo o conteúdo que não é indexado por mecanismos de busca, em contra partida a “Surface Web”, que corresponde ao conteúdo indexado e que se situaria na “superfície” da rede mundial de computadores.O artigo apontava a Deep Web como sendo 400 a 500 vezes maior que a Surface Web, a qual era composta em 95% por informações de acesso público, mas que ainda assim não podia ser acessada de formas convencionais, e sim por meio de requisições. O artigo também introduzia as seguintes imagens para ilustrar as diferenças entre Deep Web e Surface Web:



E o que exatamente estaria na Surface Web e da Deep Web? Para tanto, precisamos primeiro entender como os sites funcionam. Todo serviço na internet possui dois componentes: a interface de interação com o usuário (por exemplo, a página que você está lendo agora, o catálogo de filmes da Netflix, ou o feed de notícias do Facebook) e o sistema responsável por garantir toda a integridade do serviço (por exemplo, o banco de dados deste site, os servidores onde a Netflix armazena seus filmes e séries, ou os bancos de dados contendo todas as informações dos usuários do Facebook).
A interface com o usuário é chamada de front-end, e ela é programada justamente para permitir uma interação amigável e funcionam com o usuário, de forma que ela pode ser acessada ou por qualquer pessoa, ou por pessoas que possuam as credenciais de acesso (como logins e senhas).
Por outro lado, o sistema responsável por garantir a integridade do serviço é chamado de back-end, o qual é composto por bancos de dados e por programas que realizam o intermédio das interações entre os usuários e as bases de dados. O back-end não é programado para permitir nenhum tipo de interação direta com o usuário comum: quando este deseja receber uma dada informação das bases de dados, ele envia uma requisição através da interface, a qual é recebida por um programa que, por sua vez, irá filtrar a requisição e, se considera válida, irá acessar o banco de dados e devolver a informação desejada para a interface, que irá exibi-la para o usuário. As únicas situações em que o back-end é acessado diretamente são em invasões (nas quais o sistema que filtra tais requisições é burlado) ou em manutenções (nas quais pessoas autorizadas se conectam ao banco de dados).

Assim, o back-end armazena todo tipo de informação necessária para o funcionamento de um serviço na internet. Dentre as informações públicas, podemos citar arquivos de acesso público (como livros distribuídos gratuitamente), informações sobre preços e quantidades disponíveis de produtos em lojas virtuais, mensagens enviadas em conversas públicas etc. Dentre as informações privadas, podemos citar dados bancários, arquivos de acesso restrito, registros médicos, nomes de usuário e senhas, mensagens enviadas em conversas privadas etc. Esse conteúdo, definitivamente, é muito maior do que o conteúdo das interfaces de usuário.
Conforme talvez você tenha percebido, a definição de Deep Web cunhada por Bergman em 2001 condiz quase perfeitamente com a definição atual de back-end: a Deep Web de Bergman compreendia toda a informação armazenada no back-end, dentre a qual 95% do conteúdo correspondia à informações públicas.
Como solucionar essa confusão?
A nova definição de Deep Web
Esse é um problema complexo, mas de resolução absolutamente
necessária se quisermos realmente compreender o que é a
Deep Web e, especialmente, tornar essa compreensão mais
simples para pessoas leigas.Sendo assim, apresento-lhes uma
nova proposta, a qual procura adequar os termos já existentes, sem cunhar nenhum termo novo.
De acordo com a nova definição, a Deep Web passa a ser
definida como qualquer sistema que faça parte da rede mundial
de computadores e que garanta dois pilares para seus usuários:
a descentralização e o anonimato. Passamos a denominar a
Deep Web de Bergman apenas de back-end, que é o nome já
utilizado para a parte não indexada e diretamente inacessível
de qualquer serviço web. Passamos, então, a utilizar o termo
Surface Web para designar todo sistema que faça parte da rede
mundial de computadores e que não garanta, simultaneamente,
esses dois pilares.

Assim, todas as características que a Deep Web de Bergman possuía não mais passam a valer para a nova definição de Deep Web: esse conjunto de sistemas que a partir de agora será denominado Deep Web possui um conjunto de características completamente distinto das características originais. É justamente isso que abordaremos nas próximas seções.
Quais os papéis do anonimato e da descentralização?
Para resolver essa questão, primeiro precisamos entender como a internet – tal qual a conhecemos e acessamos diariamente – funciona.
A rede mundial de computadores pode ser representa por um grande fio, interligando diversos tipos de equipamentos. Entre eles, temos os já conhecidos servidores, a partir dos quais sites (front-end e back-end) são armazenados e operados. Temos também os clientes (computadores, tablets, celulares etc) que se conectam à internet através dos ISPs, também conhecidos como provedores de internet. Normalmente, o ISP fornece a cada usuário uma única conexão, a qual é distribuída entre diversos aparelhos através de modems e roteadores.
Cada modem conectado à rede recebe um número, denominado endereço de IP, que é utilizado para identificar a conexão e garantir que o tráfego de informações funcione corretamente. Em todos os casos, o ISP possui um registro relacionando cada endereço de IP com o usuário que o possui.
Quando uma conexão é realizada, pacotes de informação são enviados do dispositivo para o modem, do modem para o ISP e do ISP para o servidor. Este, por sua vez, também envia informações: do servidor para o ISP, do ISP para o modem e do modem para o dispositivo.

Desse funcionamento duas características ficam evidentes:
(1) Toda conexão pode ser identificada pelo seu endereço de IP, o que permite, via ordem judicial, que as pessoas por trás dessas conexões sejam identificadas. Isso também permite que os ISPs mantenham um registro dos acessos que cada conexão realizou.
(2) Todo servidor pode ser identificado por seu endereço de IP, o que permite, via ordem judicial ou chantagem, que seu respectivo serviço seja desligado da internet por alguém que não seja a pessoa responsável pelo serviço.
As redes que garantem aos usuários uma forma de contornar a característica (1) são chamadas de redes anônimas, e as redes que fornecem aos usuários uma forma de contornar a característica (2) são chamadas de redes descentralizadas. Para uma rede ser considerada parte da Deep Web ela deve não só fornecer uma forma de contornar as características (1) e (2) simultaneamente, mas também garantir que, ao fornecer a estrutura necessária para contornar uma característica, ela não viole a outra.
Assim, já podemos começar a classificar os conteúdos que normalmente encontramos na internet em cada uma dessas categoriais.
Em primeiro lugar, a maioria dos sites que você acessa (este site, Facebook, Netflix, Twitter, Gmail etc) não são nem anônimos e nem descentralizados: os usuários que os acessam podem ser facilmente identificados, assim como as pessoas por trás desses sites.
Em segundo lugar, serviços de VPNs comerciais conseguem contornar parcialmente o problema do anonimato: você não mais tem sua conexão imediatamente identificada ao acessar um determinado site. Porém, ao contornar a característica (1), tais serviços acabam por criar um servidor central que, além de poder ser localizado e retirado do ar, muitas vezes também armazena todos os IPs reais utilizados.
Em terceiro lugar, podemos mencionar o sistema de Torrents. Por meio da arquitetura descentralizada (em que arquivos são armazenados em vários computadores simultaneamente), o sistema de Torrents garante que nenhum arquivo pode ser retirado do ar, nem mesmo pelo usuário que os enviou. Porém, ao contornar a característica (2), tais serviços acabam por permitir a identificação de todos os usuários que armazenam tal arquivo.
Em quarto lugar, entram as redes da Deep Web que conseguem, com sucesso, contornar as características (1) e (2) simultaneamente sem que um método comprometa o outro. Algumas até expandem a característica (2) ao garantir que ninguém, nem mesmo o próprio usuário que fez o envio, consiga retirar um conteúdo do ar.
Existem diversas formas que uma rede da Deep Web pode aplicar para garantir o anonimato e a descentralização. Nas redes que permitem a hospedagem de serviços web (como fóruns e sites), o anonimato costuma ser garantido por técnicas como onion routing, garlic routing, agrupamento ou fragmentação de pacotes, ou, então, utilizando outra rede da Deep Web como intermediária. Já a descentralização ou é garantida de forma peer-to-peer, na qual nenhum conteúdo é hospedado em um servidor central, mas sim em fragmentos no computador dos usuários, ou é garantido pelo próprio anonimato, ao tornar o servidor central de um dado serviço não identificável.
Já nas redes que fornecem apenas a interação direta entre usuários (como compartilhamento de arquivos ou mensagens), a descentralização é obtida naturalmente ao não direcionar nenhuma mensagem para um servidor central, ao passo que o anonimato pode envolver o uso de outras redes da Deep Web, a ocultação dos endereços de IP ou a garantia de que nenhum endereço de IP é armazenado pela rede.
E quais tipos de conteúdos podem ser encontrados em cada um desses 3 tipos de redes que não fazem parte da Deep Web?
Os serviços hospedados de forma centralizada e sem anonimato correspondem a praticamente todo o conteúdo que você acessa na Surface Web: redes sociais, serviços legais de streaming, vlogs, portais de notícias, downloads, sites de empresas ou instituições, provedores de e-mail etc. Esse conteúdo é incrivelmente vasto, mas engloba, em geral, conteúdos que são legais e que envolvem pessoas que, em última instância, não se importam em serem identificadas.
Já os serviços hospedados de forma centralizada, mas anônimos correspondem principalmente às VPNs, as quais são utilizadas por pessoas que não querem ser facilmente identificadas, mas que reconhecem que, em última instância, elas ainda podem ser identificadas, ou então por pessoas que querem burlar censuras locais. Aqui entram também aqueles sites que afirmam não armazenar nenhum tipo de informação a respeito de quem os acessa.
Os serviços hospedados de forma descentralizada mas não são anônima normalmente são utilizados para pirataria, uma vez que, apesar dos detentores de direitos autorais frequentemente removerem material de serviços centralizados, eles raramente intimam um usuário identificado por compartilhar material protegido. Assim, a descentralização é fundamental, mas o anonimato pode ser dispensado – ao menos por enquanto.
Vale lembrar que, apesar das redes anônimas ou descentralizadas serem preferidas para determinados tipos de conteúdo, elas também armazenem conteúdos que não exigem o contorno de nenhuma das duas características.
E quais tipos de conteúdos podem ser encontrados nas redes da Deep Web?
Com base na afirmação anterior, todo tipo de conteúdo que já vimos até aqui também pode ser encontrado em redes da Deep Web: redes sociais, serviços legais de streaming, vlogs, portais de notícias, downloads, sites de empresas ou instituições, provedores de e-mail. De fato, grande parte do conteúdo é composto destes materiais.
Além disso, as redes da Deep Web também armazenam todo tipo de conteúdo que depende de contornar as características (1) e (2) para prosperar. Isso inclui, principalmente, todo tipo de atividade ilegal. Em minha navegação exploratória, já me deparei com as seguintes atividades, as quais estão divididas em duas colunas: ilegais e legais/pirataria.
- Pornografia ilegal, normalmente infantil ou de estupro.
- Venda de drogas;
- Venda de armas;
- Tráfico de órgãos;
- Manuais para fabricação de drogas, bombas, armas e modificações em armas;
- Manuais para cometer crimes, como estupros e assassinatos;
- Tortura e assassinato sob encomenda;
- Venda de informações bancárias de terceiros;
- Venda de dinheiro falsificado;
- Tentativa de golpes;
- Venda de caixas misteriosas com conteúdo ilegal;
- Venda de informações privilegiadas sobre governos ou corporações;
- Vazamento de informações privilegiadas;
- Venda de exploits 0-day;
- Fóruns e boards sobre práticas ilegais, onde criminosos interagem;
- Venda de medicamentos sem receita;
- Pirataria;
- Venda de documentos falsos, como passaportes e habilitação;
- Venda de produtos sem restrições alfandegárias;
- Sites que permitem financiar organizações criminosas;
- Exposição de dados pessoais;
- Serviços que fazem o intermédio de transações ilegais;
- Promoção e recrutamento de atividades terroristas;
- Sites de notícias, que provavelmente seriam censurados em seus países;
- Fóruns e boards de discussão sobre práticas não necessariamente ilegais, como hacking;
- Fóruns e boards de discussão sobre assuntos legais;
- “Confessionários”, nos quais usuários postam anonimamente;
- Páginas de cultos ou seitas;
- Plataformas para denunciantes;
- Espelhos de sites da Surface Web;
- Pornografia legal ou fetiches consensuais;
- Venda de caixas misteriosas sem conteúdo ilegal;
- Sites que agregam imagens de violência gráfica;
- Diretórios de links;
- Enigmas;
- Páginas de teste ou em branco;
- Repositórios de software;
- Bibliotecas;
- Artigos científicos;
- Livros e materiais censurados em determinados países;
- Instituições financeiras;
- Faucets de criptomoedas;
- Cassinos;
- Venda de criptomoedas;
Nesse momento, também podemos elencar alguns conteúdos que definitivamente não serão encontrados na Deep Web, assim como suas respectivas razões:
- Qualquer tipo de conteúdo de cunho paranormal ou fantástico, como a cura do câncer, a localização de Atlântida, provas da existência de vida extraterrestre e relacionados não tem maior probabilidade de serem encontrados na Deep Web do que de serem encontrados em qualquer outro lugar. Afinal, não há evidências de que essas informações possam ser encontradas em qualquer tipo de lugar.
- Informações aprofundadas sobre um determinado assunto provavelmente serão encontradas em pesquisas acadêmicas disponíveis na Surface Web, e não na Deep Web. Não há nenhum motivo pelo qual esse tipo de conteúdo necessitaria de anonimato e descentralização.
- Informações governamentais ou corporativas (como bases de dados contendo informações pessoais) não são hospedados em redes anônimas e descentralizadas, mas sim em bases de dados restritas. Você só vai encontrar essas informações na Deep Web se alguém invadir tais bases de dados e as disponibilizar na Deep Web.
- A Deep Web não é um oráculo. Se você quer encontrar algum tipo de conteúdo legal, é muito mais provável que o encontre na Surface Web, por meio da boa e velha pesquisa no Google.
- As histórias de terror envolvendo a Deep Web, como bonecas sexuais humanas, shadow web red rooms, lutas de gladiadores até a morte, centopeia humana e outras equivalentes são falsas. As três primeiras são contos que se originaram em fóruns de histórias de terror na Surface Web e se tornaram lendas urbanas. A última é apenas o tema de três filmes de ficção.


Mas quem garante que não possa existir uma rede com conteúdo sobrenatural ou de altíssimo valor?
Parte dessa resposta já foi dada: simplesmente não existem razões para que alguém programe uma rede do tipo. Se o objetivo é criar um sistema suficientemente seguro para armazenar dados confidenciais, a melhor alternativa é a construção de um prédio físico com servidores e acesso de pessoas controlado e, evidentemente, sem conexão com a internet. É o que a NSA, por exemplo, fez.
A segunda parte dessa resposta é mais um conceito filosófico do que prático. Certamente, existem coisas que não conhecemos: existem casas na sua vizinhança nas quais você nunca entrou e existem planetas no universo que não conhecemos.
É possível que esses lugares que não conhecemos contenham algo fora do normal? Sim, sempre é possível. Seu vizinho pode ter um corpo escondido na garagem, ou um planeta desconhecido pode abrigar vida. Porém, é estatisticamente mais provável que seu vizinho e esse planeta sejam mais ou menos semelhantes aos outros que nós já conhecemos. Além disso, o desconhecido muito, muito provavelmente não viola nenhuma lei natural. Seu vizinho definitivamente não tem um dragão na garagem, e esse planeta definitivamente não abriga uma população composta somente por clones do Felipe Melo.
O mesmo vale para as redes da Deep Web. Conteúdos sobrenaturais muito, muito provavelmente não estão em nenhuma rede da Deep Web desconhecida até o momento. Porém, existem dezenas de redes já documentadas, outras ainda para serem documentadas, e novas redes podem surgir a qualquer momento. É estatisticamente provável que essas redes sejam como as demais redes anônimas e descentralizadas que conhecemos até o momento, mas a exploração é e sempre será um processo contínuo.
Como eu acesso a Deep Web?
A pergunta que abre essa seção só pode ser respondida com outra pergunta: qual rede você pretende acessar?
A rede mais popular, mais utilizada e que na maioria das vezes é o ponto de entrada é a rede Onion, a qual é acessível por meio da instalação do navegador Tor, ou de softwares equivalentes que realizam o mesmo processo em outras plataformas. Para aprender como acessá-la, você pode seguir os tutoriais presentes na seção de redes documentadas.
Assim, acesse o menu de rede documentadas e procure pela rede que deseja acessar. Pessoalmente, eu também recomendo a Tor: além de mais popular, é a rede com maior volume de conteúdo, com mais fóruns de discussão fora dela e com menor incidência de erros dentre os demais projetos. Na página específica da rede Tor, você será redirecionado à todas as informações que precisa para realizar o acesso: o download de um navegador específico e algumas instruções básicas sobre seu funcionamento.
Como eu devo me preparar para acessar a Deep Web? Devo usar máquina virtual, antivírus, VPN?
Uma boa forma de preparação é ler esse artigo até o fim antes de seu primeiro acesso. Ademais, as informações adicionais necessárias já estão na página de cada uma das redes.
É chegado, então, o momento de desmistificar mais um conceito: o de que navegação na Deep Web é muito mais perigosa que a navegação na Surface Web. Muitas pessoas acreditam que a Deep Web é um território repleto de hackers, espiões e agentes do FBI prontos para pegar qualquer descuido seu e bater na sua porta. Isso é mentira.
As duas principais características de qualquer rede da Deep Web são a descentralização e o anonimato. Essas características valem para absolutamente qualquer pessoa que acessa determinada rede, seja ela um criminoso, um agente do FBI, ou você. Todos os usuários de uma dada rede da Deep Web (e isso é especialmente válido para a Tor) estão protegidos e com suas identidades ocultadas no momento em que realizam o acesso. Não há como ninguém te localizar nesse momento.
O jeito para se manter anônimo durante todo o acesso está justamente na forma como você vai interagir com os sites, pessoas e serviços na Deep Web. A seguir, apresentarei diversas recomendações que você deve seguir ao navegar em qualquer rede da Deep Web, a menos que você realmente saiba o que está fazendo.
A primeira delas, e mais óbvia, é não revelar na Deep Web (seja através de mensagens, em conversas, ao preencher formulários ou fazer cadastros) nenhuma informação sua que possa estar, de alguma forma, relacionada com qualquer tipo de serviço que você utiliza na Surface Web. Ou seja, jamais informe seu nome, telefone, e-mail, ou perfis de qualquer tipo. Se você precisar informar algum dado do tipo, utilize pseudônimos, informações incorretas ou e-mails criados na própria Deep Web.
A segunda é a respeito de plugins e extensões: nas redes que envolvem navegação em sites, evite ao máximo utilizar extensões (como as de navegador que você usa na Surface Web), plugins (como o Javascript, ou o Adobe Flash Player) ou qualquer outro programa de terceiros que não seja explicitamente endossado pelos desenvolvedores da rede. Tais programas podem conter vulnerabilidades que permitam a quebra do anonimato.
A terceira é a respeito de vírus e programas maliciosos que podem danificar seu computador ou revelar sua identidade real. Tais programas só podem entrar em sua máquina se você baixar e executar algum arquivo, e isso vale tanto para a Surface Web quanto para qualquer rede da Deep Web. Logo, a recomendação mais genérica é: não faça nenhum tipo de download na Deep Web.
Porém, muitas vezes nós queremos fazer downloads, e é perfeitamente possível fazer isso em segurança. Porém, entender como envolve, antes, entender algumas noções de computação.
O primeiro caso que abordaremos é em relação à como que o download de arquivos podem causar danos ao seu computador.
Primeiramente, é importante lembrar que os arquivos na Deep Web não são mais perigosos nesse quesito do que os arquivos oriundos de qualquer outro lugar. O risco e a quantidade de arquivos maliciosos presentes em cada uma das redes são exatamente os mesmos. Portanto, nenhuma medida de segurança além das que você já utiliza na Surface Web são necessárias.
A imagem abaixo ilustra como seu computador funciona. Dentre os elementos notáveis, podemos destacar a internet, um firewall (que pode ser tanto um software comercial quanto ferramentas nativas), os diversos programas que se conectam à internet (cada um representando por um espaço vermelho), os arquivos do computador e um antivírus (que também pode ser tanto um software comercial quanto ferramentas nativas).

O antivírus age como um filtro que checa os arquivos que entram na máquina, eliminando aqueles considerados maliciosos e permitindo a entrada daqueles considerados seguros. Adicionalmente, o antivírus também pode procurar por atividades suspeitas já dentro da máquina.
Os programas autorizados funcionam no computador, e se conectam com a internet para enviar e receber informações. Esse tráfego é filtrado pelo firewall, que bloqueia as conexões consideradas suspeitas e permite aquelas consideradas seguras, tanto de entrada quanto de saída.


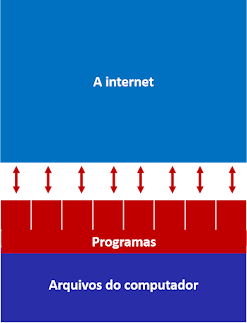
Quando você inicia uma rede da Deep Web (neste exemplo, estamos considerando a Tor, mas isso vale para praticamente todas as outras redes), você cria um canal entre aquele programa (no nosso caso, o Tor Browser) e a internet.
Como as redes da Deep Web são anônimas, os pacotes que trafegam nesse canal utilizam outro endereço de IP, diferente do seu endereço de IP real, que permanece oculto e não pode ser visualizado pelos receptores dos pacotes, situados na internet.
É por meio desse canal que você, ao utilizar a Deep Web, terá acesso aos sites, conversará com outros usuários e baixará arquivos.




- Se você pretende apenas entrar em uma rede para navegar e participar de interações, mas sem o download de arquivos, use os recursos de segurança que você já está acostumado a utilizar. Não instale nem remova nenhuma ferramenta, e siga as instruções gerais de compartilhamento de arquivos.
- Se você pretende baixar arquivos, mas não tem nenhuma noção de como discernir qual arquivo é malicioso e qual não é, não baixe arquivos, ou instale uma máquina virtual com Whonix, Torfier ou Tails. Ao final do uso, delete a máquina virtual.
- Se você pretende baixar arquivos e se considera apto para discernir qual arquivo é malicioso e qual não é, prepare um ambiente com uma máquina virtual e uma VPN descentralizada caso se importe com o anonimato e suspeite de algo que possa quebrá-lo. Use-a quando necessário e, caso se sentir apto, execute os arquivos que considera seguros na própria máquina nativa. Não instale nem remova nada além do que você já costuma usar na máquina nativa.
- Se você pretende fazer algo que definitivamente exija anonimato e ausência de vestígios, instale o Tails em uma unidade removível (como um pen-drive ou CD) e use-o para seus fins. Ao final do processo, destrua a unidade: jogue-a no mar, queime-a, ou algo equivalente.
 BOA NAVEGAÇÃO PRA VOCÊS
BOA NAVEGAÇÃO PRA VOCÊS










![😈💥 SCRIPT HACK FACEBOOK [2020] PARA TERMUX - FUNCIONANDO 😈💥](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_t-UvgXKK7BpasxdnJxmHXMqfZIq4NWmum2HAcui5BwQdWs_133AL6QQ1B77zBhUD43bw04-MRiQTs2ne2P9ziz1xSJL2_8j50FgyvoObD10PF5gps=w100)


{kind=link}
0 Comentários